

# 从零开始做生信分析(一):选题、数据下载与预处理
## 一、R软件安装
R是生信分析的核心工具,下载地址:https://cran.r-project.org/
Windows用户下载后运行安装程序即可。安装完成后,建议同时安装RStudio(https://posit.co/download/rstudio/),这是R的图形化界面,操作更便捷。
首次使用前,在RStudio控制台安装生信分析所需包:
“`r
install.packages(c(“GEOquery”, “limma”, “clusterProfiler”, “org.Mm.eg.db”))
“`
—按照生信课的意思是都安装到一个文件夹中。
## 二、选题与研究设计
生信分析的第一步是明确研究问题。以阻塞性睡眠呼吸暂停(OSA)为例,可以提出科学假设:慢性间歇性低氧(IH)是否通过特定通路导致认知障碍?
选题原则:
– **聚焦临床问题**:OSA相关认知障碍是常见临床难题
– **有公共数据支持**:GEO数据库中有多个IH相关数据集
– **可结合湿实验验证**:生信结果需后续动物实验验证
—
## 三、GEO数据库数据下载
GEO(Gene Expression Omnibus)是全球最大的基因表达公共数据库。进入https://www.ncbi.nlm.nih.gov/geo/,搜索关键词如”intermittent hypoxia cognitive impairment”,可找到相关数据集。
以GSE299437为例:
“`r
library(GEOquery)
gse299437 <- getGEO(“GSE299437”, AnnotGPL = TRUE, getGPL = TRUE)
gse299437 <- gse299437[[1]]
“`
下载后,通过`exprs()`获取表达矩阵,`pData()`获取样本信息。
—生信课上以可视化操作为主,还是很方便。
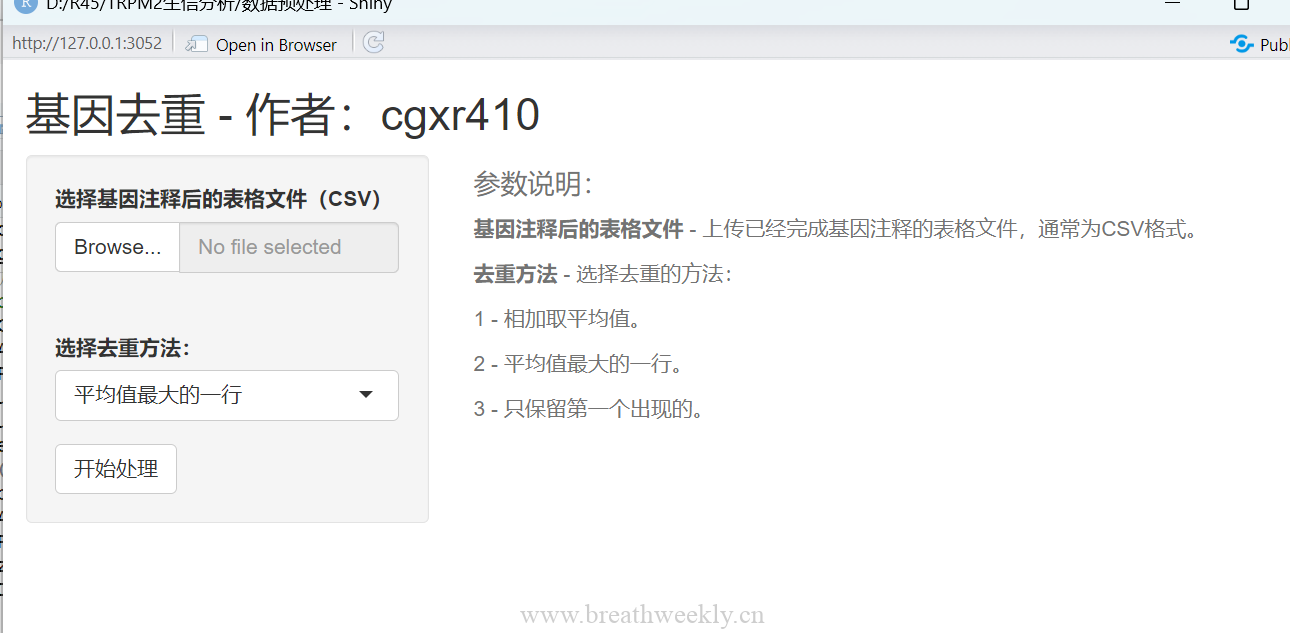
## 四、数据预处理
原始数据需预处理后才能进行差异分析:
**1. 质量控制**:检查样本表达量分布,剔除异常样本
**2. 缺失值处理**:可用`na.omit()`或插值法填补
**3. 归一化**:去除批次效应,使样本间可比较

“`r
# 归一化(log2转换)
expr_normalized <- log2(exprs(gse299437) + 1)
# 分组信息
group <- ifelse(grepl(“CIH”, pData(gse299437)$title), “CIH”, “NC”)
“`
**4. 过滤低表达基因**:保留在多数样本中表达的基因
预处理是整个分析的基础,数据质量决定结果的可信度,需认真对待。
—
*下一篇将从差异分析、GO/KEGG富集分析继续讲解生信实战技巧。*


没有回复内容